
WhatsApp een scriptiebegeleider
0614592593
Bij het uitvoeren van een (survey) onderzoek worden gegevens van respondenten verzameld die nodig zijn voor het beantwoorden van onderzoeksvragen en het testen van hypotheses. Soms staan er echter gegevens in de datasets die de privacy van de respondenten kunnen bedreigen en die niet als zodanig nodig zijn voor het uitvoeren van statistische analyses. Niet alleen om de belofte aan respondenten dat hun gegevens anoniem verwerkt zullen worden te waarborgen, maar ook om te voldoen aan de wet AVG, is het van belang om te zorgen dat je dataset ook écht anoniem is voordat je deze doorstuurt of overdraagt.
Hieronder worden enkele vaker voorkomende, soms overduidelijke en andere minder duidelijke, zaken genoemd die de privacy van participanten kunnen bedreigen. Hierbij wordt een SPSS-dataset als voorbeeld genomen maar, hoewel de aanpak in andere statistische programma’s verschilt, is de gedachtegang erachter veelal hetzelfde.
Hopelijk inspireert deze pagina tot het kritisch bekijken van je dataset en krijg je ideeën over hoe je op een veilige manier kunt omgaan met de gegevens die respondenten je hebben toevertrouwd. De volgende onderwerpen komen aan de orde:
![]() Ip-adressen
Ip-adressen
![]() Email-adressen
Email-adressen
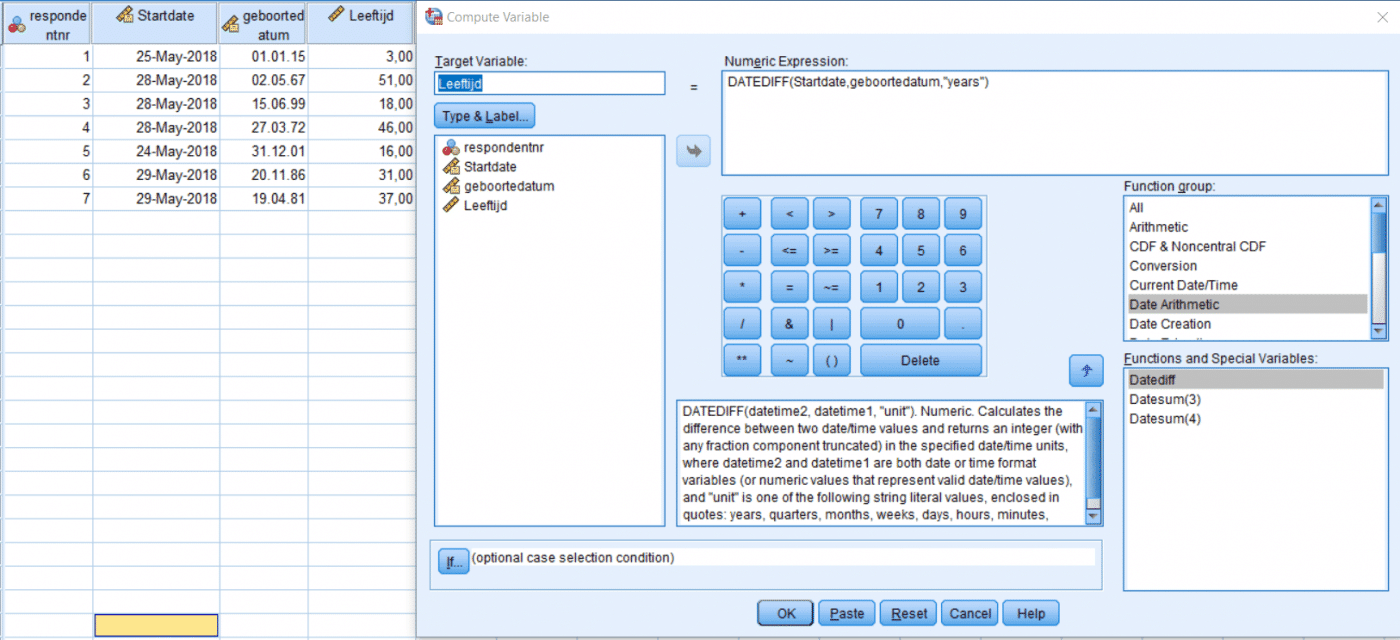
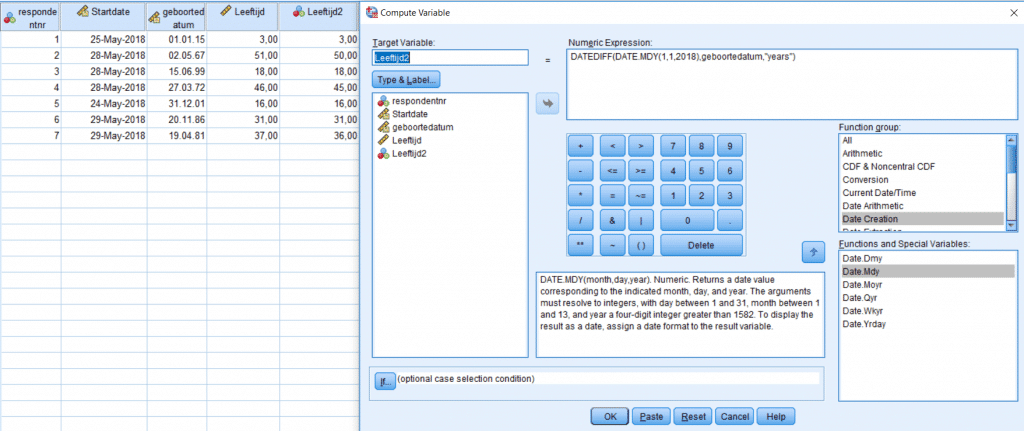
![]() Geboortedatum
Geboortedatum
![]() Overige gegevens en Bedrijfsgegevens
Overige gegevens en Bedrijfsgegevens
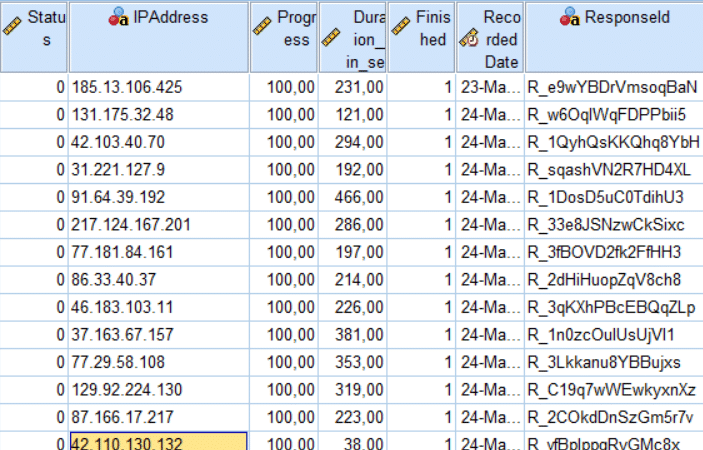
Naast bovengenoemde veelvoorkomende situaties, kunnen er nog andere gegevens in datasets terecht komen die de anonimiteit van de respondent bedreigen. Bijvoorbeeld sommige enquêtetools verzamelen ook Latitude en Longitude van de locatie waar de respondent de vragenlijst invulde. Voor de meeste onderzoekers zullen deze variabelen niet relevant zijn en dienen ze uit de dataset verwijderd worden.
Daarnaast kun je in jouw dataset ook bedrijfsgegevens hebben verzameld. Bedrijfsnamen in combinatie met bijvoorbeeld de leeftijd van een respondent, is een risico. Het beste is om ook bedrijfsnamen eruit te halen en te vervangen door een identificatienummer (die jij als onderzoeker alleen hebt genoteerd).
![]() De algemene regel is dan ook: Kijk kritisch naar je dataset voordat je deze deelt met andere personen. Als er variabelen zijn die de anonimiteit van je respondenten, op welke manier dan ook, kunnen bedreigen, neem dan passende maatregelen.
De algemene regel is dan ook: Kijk kritisch naar je dataset voordat je deze deelt met andere personen. Als er variabelen zijn die de anonimiteit van je respondenten, op welke manier dan ook, kunnen bedreigen, neem dan passende maatregelen.
Zo kun je de (beloofde) anonimiteit van je respondenten garanderen. Wil je verder lezen over hoe je een start kunt maken met de analyses? Lees dan ook eens onze SPSS tips.
WhatsApp een scriptiebegeleider
0614592593